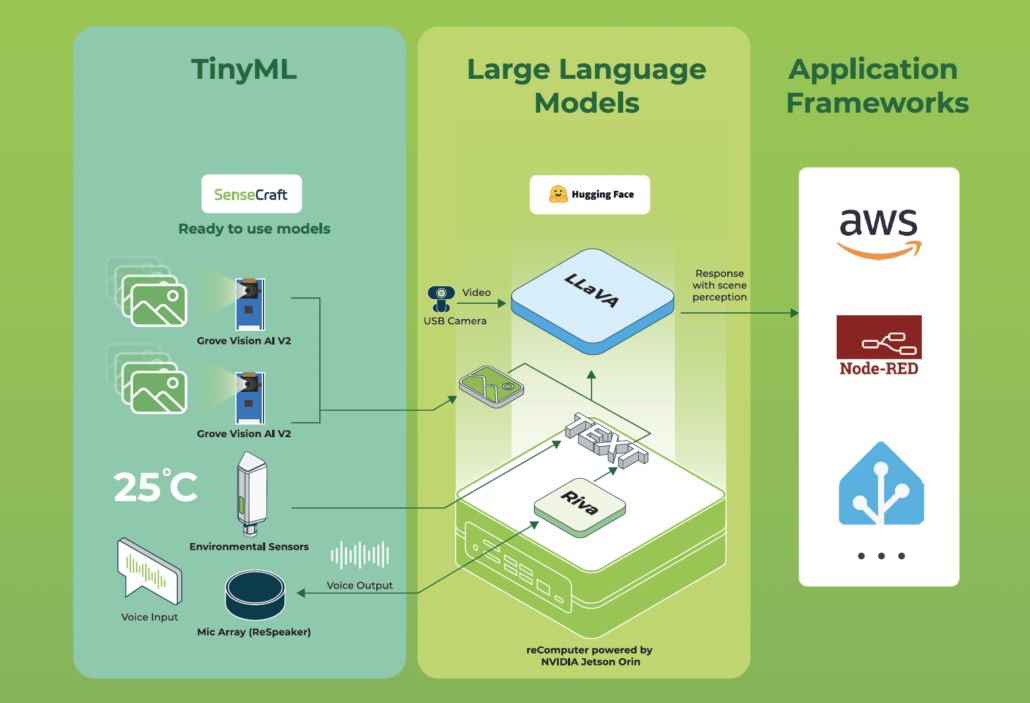
TinyML + Local LLMs: A Trendy Architecture for Efficient and Affordable Edge AI







Notifications