Build a Local RAG Chatbot on Jetson Orin for Your Knowledge Base
Retrieval-augmented generation (RAG) technology integrates the capabilities of retrieval and generation models into Large Language Models (LLMs), enhancing their adaptability and responsiveness to constantly evolving demands. This innovative approach allows LLM to dynamically access a local knowledge library for relevant, up-to-date responses, making them more agile and effective in addressing new challenges. The use of RAG not only improves response quality but also maximizes the value derived from LLMs, facilitating smarter, context-aware interactions across various business applications, thereby promising a significant shift in how enterprises leverage language processing for greater success.
How Does RAG Work?
Introduced by Facebook AI Research in 2020, RAG is designed to optimize the output of LLM using dynamic, domain-specific data without requiring retraining. RAG features an end-to-end architecture that integrates an information retrieval component with a response generator, enabling the model to access and incorporate relevant information in real time to enhance its responses.
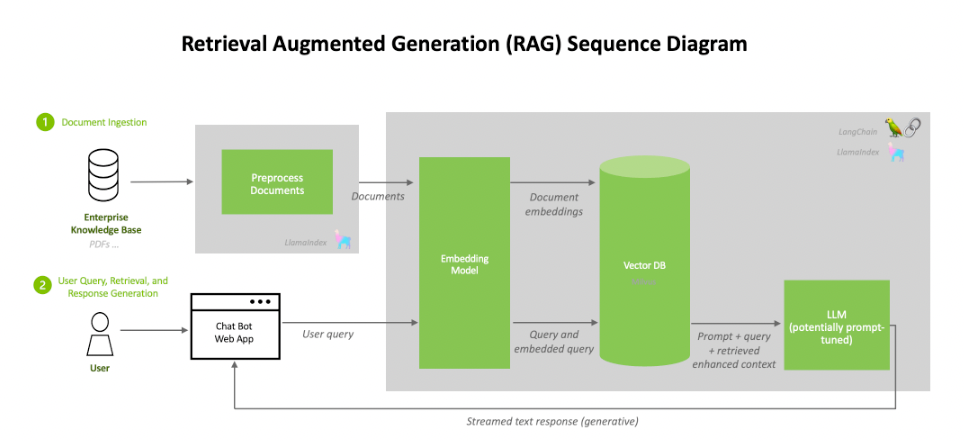
RAG Pipeline Overview
- Embedding Data: A specialized model processes various types of data, including images, text, audio, and video, converting them into vectors. These vectors are then stored in a vector database.
- Input Processing: Whether the input is text or images, it undergoes the same embedding process to transform into a vector.
- Vector Matching: The system searches the vector database to identify the top K vectors most similar to the input vector.
- Contextual Response Generation: The documents linked to these top vectors serve as context for a language model, which then crafts responses that are informed by this relevant context.
What Can RAG Bring to You?
Almost every enterprise now manages large datasets relevant to their business, ranging from product manuals in tech companies to case data in law firms and patient records in hospitals. As these datasets grow, it becomes impractical for even the most knowledgeable employees to remember every detail, often leading to time-consuming data searches during customer interactions or internal queries.

Using LLM can streamline this process by allowing employees and customers to query directly and receive immediate answers. However, LLM can sometimes produce convincing yet incorrect answers, a phenomenon known as hallucination. RAG helps mitigate this by feeding LLM with updated, accurate data, enhancing the reliability and contextuality of the responses. This integration of RAG and LLM not only improves workflow efficiency but also elevates the customer experience by ensuring that the provided information is both precise and relevant as the latest.
Why Do You Need Local RAG?
We know that RAG plays a pivotal role in managing huge amounts of data from companies and government agencies effectively, however, the data stored by these entities is often expected to be confidential and not meant for external access. Deploying cloud-based LLM and vector databases can pose a risk of data leakage. To prevent this, it’s essential to implement the vector database and LLM on-premises.
By setting up the vector database and large language model on-premises, we effectively shield sensitive data from external threats, and also significantly reduce the latency issues occurring due to bandwidth and network constraints when data is processed remotely; local processing means information is accessed swiftly and securely. In essence, using local RAG not only safeguards data but also optimizes the responsiveness of language model processing, making it a robust solution for handling sensitive and extensive datasets.
Get Hands-on Local RAG with Jetson Orin
Context search with a local chatbot:
Here’s our demo featuring the Llama2-7b model, optimized through MLC technology for efficient 4-bit quantization. This approach enhances data processing speeds while maintaining high accuracy. We utilize ChromaDB, a high-performance vector database, ensuring fast retrieval and scalable storage solutions, fully integrated through Llama_Index for seamless data synchronization and indexing. The entire system is powered by the reComputer J4012, which utilizes the potent NVIDIA Jetson Orin NX 16GB module, offering exceptional computational power and energy efficiency, making it ideal for real-time AI applications. For a deeper dive into our technology stack and to access the tools necessary for deployment, visit our comprehensive GitHub repository.
Image search through the database:
Explore the demo showcased from the NVIDIA Jetson AI Lab, demonstrating cutting-edge multimodal RAG for one-shot classification and recognition. This powerful system utilizes CLIP alongside dynamic Vision and Language Models (VLM) for real-time processing. It efficiently tags and recognizes content by analyzing image metadata stored in VectorDB during runtime. This sophisticated integration showcases the potential of advanced AI in handling and interpreting multimodal data seamlessly.
Fast response and notification:
This demo highlights the enhanced capabilities of live Llava and web UI, featuring advanced multimodal RAG and seamless integration with VILA (on pre-training VLM). The system offers event filtering and configurable triggers for actions and alerts, empowering users to dynamically adjust image queries, develop intelligent cameras, and incorporate custom code to further personalize alert or action mechanisms.
Seeed NVIDIA Jetson Ecosystem
Seeed is an Elite partner for edge AI in the NVIDIA Partner Network. Explore more carrier boards, full system devices, customization services, use cases, and developer tools on Seeed’s NVIDIA Jetson ecosystem page.
Join the forefront of AI innovation with us! Harness the power of cutting-edge hardware and technology to revolutionize the deployment of machine learning in the real world across industries. Be a part of our mission to provide developers and enterprises with the best ML solutions available. Check out our successful case study catalog to discover more edge AI possibilities!
Discover infinite computer vision application possibilities through our vision AI resource hub!
Take the first step and send us an email at edgeai@seeed.cc to become a part of this exciting journey!
Download our latest Jetson Catalog to find one option that suits you well. If you can’t find the off-the-shelf Jetson hardware solution for your needs, please check out our customization services, and submit a new product inquiry to us at odm@seeed.cc for evaluation.
