Faster YOLOv5 inference with TensorRT, Run YOLOv5 at 27 FPS on Jetson Nano!

Why use TensorRT?
TensorRT-based applications perform up to 36x faster than CPU-only platforms during inference. It has a low response time of under 7ms and can perform target-specific optimizations. Thus enabling developers to optimize neural network models trained on all major frameworks, such as PyTorch, TensorFlow, ONNX, and Matlab, for faster inference. It can also be integrated with application-specific software development kits such as NVIDIA DeepStream, Riva, Merlin, Maxine, Modulus, Morpheus, and Broadcast Engine.
How does TensorRT perform optimization?
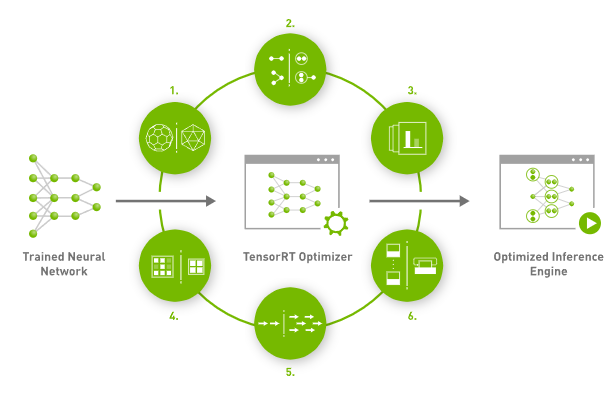
We have read about how TensorRT can help developers optimize, but now we will look at the six processes of TensorRT that can make it work.
1. Weight & Activation Precision Calibration

Nearly all deep learning models are trained in FP32 to take advantage of a wider dynamic range. However, these models require a long predicting time, setting back real-time responses.
In this process, model quantization converts the parameters and activations to FP16 or INT8. This will normally cause lower accuracy and a reduction in latency and model size. But by using KL-divergence, TensorRT is able to measure the difference and minimize it, thereby preserving accuracy while maximizing throughput. We can see the difference between FP32 and INT8/FP16 from the picture above.
2. Layer & Tensor Fusion

In this process, TensorRT uses layers and tensor fusion to optimize the GPU’s memory and bandwidth by fusing nodes in a kernel vertically or horizontally (sometimes both). This reduces the overhead cost of reading and writing the tensor data for each layer.
We can see from the picture above that TensorRT recognizes all layers with similar inputs and filter sizes and merges them to form a single layer. It also eliminates concatenation layers, as seen in the picture above (“concat”).
Overall, this will result in a smaller, faster, and more efficient graph with fewer layers and kernel launches, which will reduce inference latency.
3. Kernel Auto-Tuning
During this process, TensorRT selects the best layers, algorithms, and batch size based on the target GPU platform in order to find the best performance. This ensures that the deployed model is tuned for each deployment platform.
4. Dynamic Tensor Memory
For this process, TensorRT minimizes memory footprint and re-uses memory by allocating memory for each tensor only for the duration of its usage, avoiding any memory allocation overhead for faster and more efficient execution.
5. Multi-Stream Execution
TensorRT is designed to process multiple input streams in parallel during this process.
6. Time Fusion
For the last step before heading to the output stage, TensorRT is able to optimize recurrent neural networks over time steps with dynamically generated kernels.
What models can be converted to TensorRT
TensorRT officially supports the conversion of models such as Caffe, TensorFlow, PyTorch, and ONNX.
It also provides three ways to convert models:
- Integrate TensorRT in TensorFlow using TF-TRT.
- torch2trt: PyTorch to TensorRT converter, which utilizes the TensorRT Python API.
- Construct the model structure, and then manually move the weight information, tensorrtx: implement popular deep learning networks with TensorRT network definition APIs.
What does this mean for NVIDIA Jetson?
Note: All models are run on FP32 precision
NVIDIA Jetson is a family of embedded devices with the ability to run AI at the edge. When you compare with traditional systems that can do AI inference, such as a desktop PC with a GPU, Jetson devices are very small. However, the performance is limited compared with those big systems. To get the best performance out of these Jetson systems, the implementation of TensorRT is very helpful.
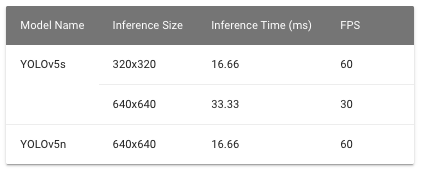
Now let us compare how much of a performance increase we can expect by using TensorRT on a Jetson device. As an example, we have run inference using YOLOv5 on a Jetson Nano device and checked the inference performance with and without TensorRT.
For inference without TensorRT, we used ultralytics/yolov5 repo with the yolov5n pre-trained model
- Step 1: Refer to step 1 – step 8 in this wiki section
- Step 2: Connect a webcam to the Jetson device and run the following inside the YOLOv5 directory
python3 detect.py –source 0 –weights yolov5n.pt
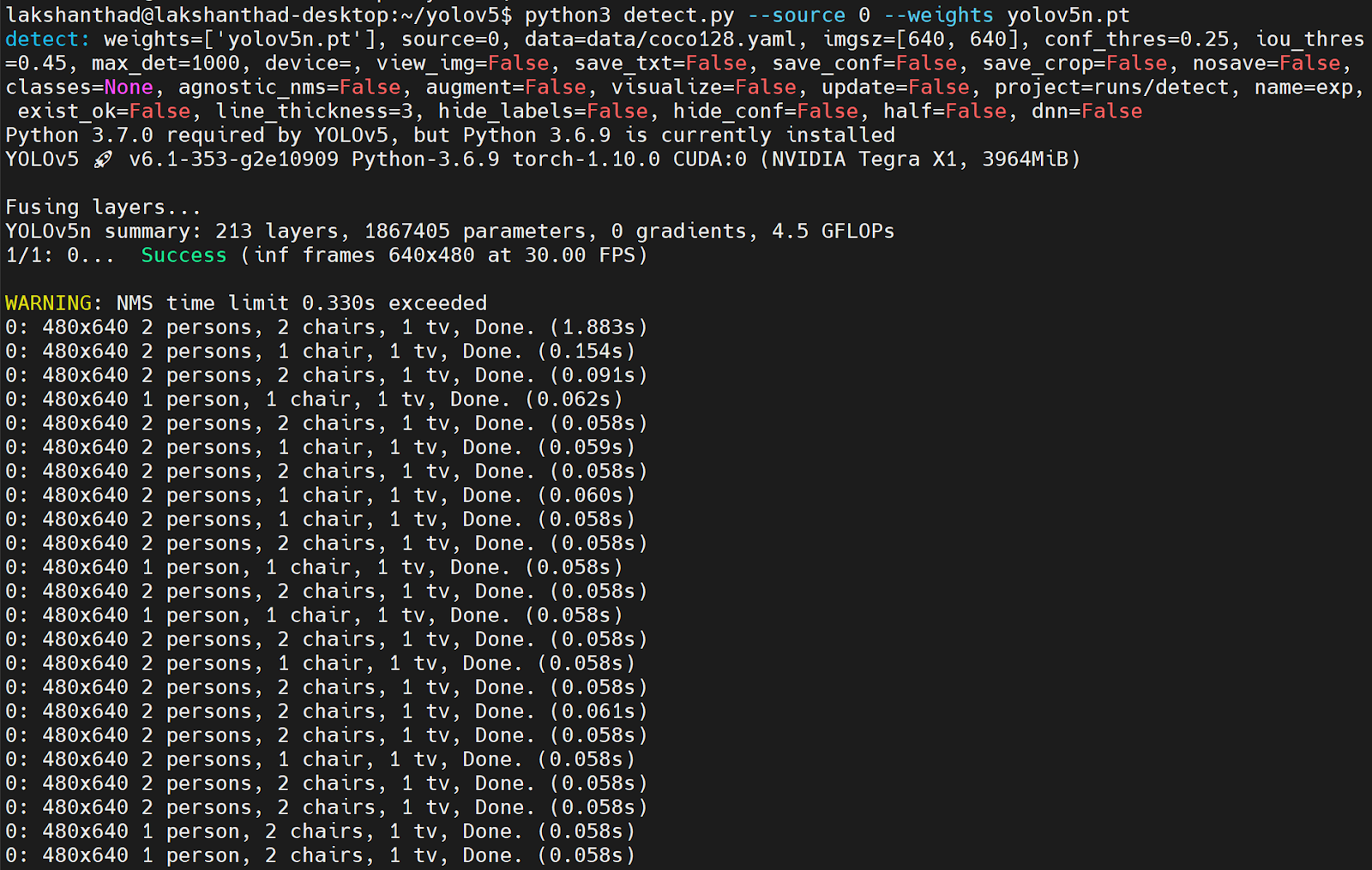
As you can see, the inference time is about 0.060s = 60ms, which is nearly 1000/60 = 16.7fps
For inference with TensorRT, we used ultralytics/yolov5 repo in combination with wang-xinyu/tensorrtx repo with the yolov5n pre-trained model
- Step 1: Refer to step 1 – step 20 in this wiki section
- Step 2: Run the following with the required images for inference loaded into “images” directory
sudo ./yolov5 -d yolov5n.engine images

As you can see, the inference time is about 0.037s = 37ms which is nearly 1000/37 = 27fps
We have also run inference using YOLOv5n pre-trained model on a Jetson Xavier NX device and checked the inference performance with TensorRT. Here we used ultralytics/yolov5 repo in combination with marcoslucianops/DeepStream-Yolo repo with the yolov5n pre-trained model
- Step 1: Refer to step 1 – step 10 in this wiki section
- Step 2: Run the following to view the inference
deepstream-app -c deepstream_app_config.txt
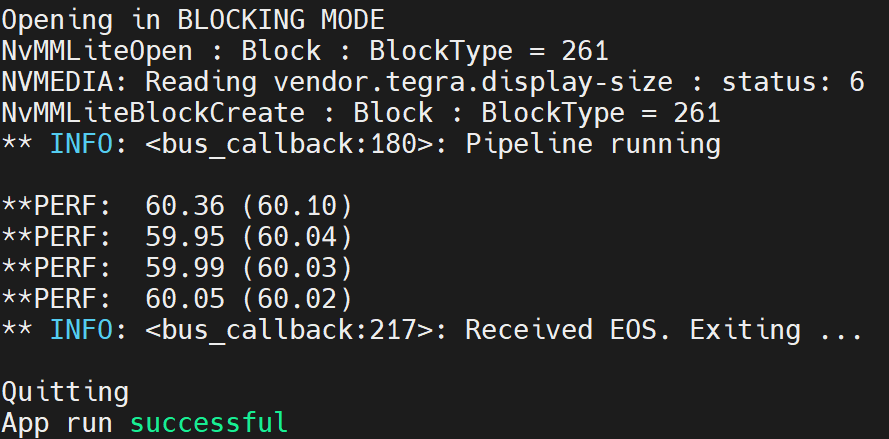
The above result is running on Jetson Xavier NX with FP32. We can see that the FPS is around 60.
So we can conclude that even on the Jetson platform if you use TensorRT, you can get a much better inference performance on computer vision tasks!
We also recommend you check Deci Platform for Fast Conversion to TensorRT™
The table below summarizes the optimization results and proves that the optimized TensorRT™ model is better at inference in every way.

TensorRT and NVIDIA Jetson Projects
Get started with Hello AI World

Hello AI World is a guide to deploying deep-learning inference networks and deep vision primitives with TensorRT and NVIDIA Jetson. It will show you how to use TensorRT to efficiently deploy neural networks onto the embedded Jetson platform, improving performance and power efficiency using graph optimizations, kernel fusion, and FP16/INT8 precision.
This guide would mainly cover image classification, object detection, semantic segmentation, pose estimation, and mono depth. Video tutorials for each model can be found in this GitHub link.
MMDetection is an open-source object detection toolbox based on the previously mentioned PyTorch. It consists of training recipes, pre-trained models, and dataset support. It runs on Linux, Windows, and macOS and requires Python 3.6+, CUDA 9.2+, and PyTorch 1.5+. They have also released a library mmcv, for computer vision research. Through the method of module calling, we can implement a new algorithm with a small amount of code. Greatly improve the code reuse rate.

MMDeploy is an open-source deep learning model deployment toolset. It is a part of the OpenMMLab project. Check this guide to learn how to install MMDeploy on NVIDIA Jetson edge platforms such as Seeed’s reComputer.
The Model Converter of MMDeploy on Jetson platforms depends on MMCV and the inference engine TensorRT. While MMDeploy C/C++ Inference SDK relies on spdlog, OpenCV and ppl.cv, as well as TensorRT.
Automatic License Plate Recognition

Lima, the capital city of Peru, has the third worst traffic in the world in 2018. Thus, they implemented a driving restriction policy where on Monday and Wednesday, only odd-number license plates are allowed, and on Tuesday and Thursday, only even-number license plates can drive out. As of now, traffic police officers are checking manually on the streets, which is time-consuming and a waste of taxpayer money. With automation, manual labor can be reduced to a minimum, and all spots on the highway can be detected as well!
This solution is portable and cheap and can be used for other cities that are facing similar traffic congestion issues. The webcam would capture real-time video of the streets and detect the cars and their license plates using a Mobilenet SSD model optimized for TensorRT. It will then be sent to the OpenALPR module to check if it is compliant with the law on different days. A buzzer will also sound out once an offender is detected.
Here’s what you need for this project:
- NVIDIA Jetson Nano/ reComputer J1010
- 16×2 LCD
- USB Webcam
- Buzzer
- TensorFlow
- TensorRT
- pycuda
- LLVM
- Numba
- scikit-learn
- SciPy
- OpenALPR
Traffic Light Management
After an ALPR project, you can try your hand at traffic light management which also aims to reduce traffic congestion!

Traffic lights are the main causes of traffic bottlenecks if not done properly. This project seeks to solve such issues using DeepSORT object tracking algorithm based on YOLOv4 to ensure a real-time response. TensorRT was used for optimization and quantization on Jetson Xavier NX.
Here’s what you need for this project:
- NVIDIA Jetson Xavier NX/ reComputer J2012 (Jetson Xavier NX)
- Intel Neural Compute Stick 2
- Raspberry Pi 4 Model B
- USB Multifunction Tester
- TensorFlow
- TensorRT
- OpenVINO
- Raspberry Pi Raspbian
- DeepSORT
- YOLOv4
Real-Time People Tracking & Counting
This project is able to detect real-time information about people coming in and out of a certain location (indicated by a line). It is significantly better and cheaper than hiring a human counter standing by a mall entrance. It is less prone to human errors, and costs will be significantly lower.
Here’s what you need for this project:
- NVIDIA Jetson Nano/ reComputer J1010 (Jetson Nano)
- Raspberry Pi Camera / USB Webcam
- TensorRT
- JetPack
Pothole Detector

Potholes damage cars and can cause cracks and bends on rims which will affect the wheel alignment and cost a significant amount of money to change out. This project seeks to help the government or local authorities to seek out potholes and prevent this issue from ever happening.
Here’s what you need for this project:
- NVIDIA Jetson Nano/ reComputer J1010 (Jetson Nano)
- Raspberry Pi Camera / USB Webcam
- TensorRT
- TensorFlow
Leukemia Classifier
This medical support project is to detect Acute Lymphoblastic Leukemia (ALL). ALL is the most common leukemia in children and accounts for up to 20% of acute leukemia in adults. It was developed using Intel’s oneAPI and Optimization. TensorRT was used for high-performance inference on Jetson Nano to accelerate the training process.
However, a few disclaimers about this project:
- Even though this model may be accurate and shows good results on paper and in real-world testing, it is trained on a small set of data.
- No doctors, medical or cancer experts were involved in contributing to this repository.
Here’s what you need for this project:
- NVIDIA Jetson Nano/ reComputer J1010.
- Intel NUC Kit
- Intel oneAPI
- TensorFlow
- TensorFlow RunTime
- TensorRT
- ONNX
Face Mask Detection System
With the Covid-19 pandemic, everyone is wearing a face mask nowadays. Thus many facial recognition technologies are finding it very hard to detect faces.
This project uses the SSD-MobileNet algorithm, which is the fastest model available for the single-shot method on NVIDIA Jetson boards. It also uses the Kaggle dataset, which can be downloaded here. TensorRT was used to improve detection time, allowing Jetson Xavier NX to achieve higher than 100FPS.
Here’s what you need for this project:
- NVIDIA Jetson Nano/ reComputer J1010 (Jetson Nano) (this project used NVIDIA Jetson Xavier NX/ reComputer J2012 (Jetson Xavier NX))
- Raspberry Pi Camera (this project used a USB Webcam)
- PyTorch
- TensorRT
Safety Helmet Detection System
Safety helmets are the most important equipment in industrial places to protect workers against accidents. This project would seek to detect whether the workers are abiding and wearing their safety helmets during work. It uses the latest YOLOv7 to train a custom object detection model to detect workers wearing safety helmets, and TensorRT was used to run the deep learning platform.
Here’s what you need for this project:
- NVIDIA Jetson Nano / NVIDIA Jetson Xavier NX/ reComputer J1010 (Jetson Nano)/ reComputer J2012 (Jetson Xavier NX)
- Microsoft VScode
- YOLOv7
- TensorRT
DeepStream Video Analytics Robot

Source: Attila Tőkés
Deep Eye, the robot above, is a rapid prototyping platform for NVIDIA DeepStream-based video analytics application. TensorRT allowed Deep Eye to implement hardware-accelerated inference and detection.
There are 3 main components:
- Hardware platform to be used with Jetson Nano
- DeepLib, an easy to use python library which allows for easy DeepStream-based video processing
- Web IDE that allows easy creation of DeepStream-based application
Here’s what you need for this project:
- NVIDIA Jetson Nano/ reComputer J1010 (Jetson Nano)
- Raspberry Pi Camera
- SG90 Micro Servo Motor
- Stepper Motor
- Adafruit 16-Channel 12-bit PWM/Servo Shield – I2C interface
- A4988 Stepper motor driver board
- Prototype (designed in FreeCAD, tutorial found here)
- JetPack
- DeepStream SDK
- DeepStream Python Bindings
- TensorRT
- SDK Manager
Action Tracking & Activity Recognition
This intelligent video analytics project will seek to perform multi-person tracking and activity recognition. Firstly, they used OpenCV to acquire and process videos. Next, they used Openpose for pose estimation, and to track person instances, they used a scikit-learn implementation. Together with TensorRT converters for optimized inference on Jetson Nano, they have successfully completed their tracking and recognition project.
Here’s what you need for this project:
- NVIDIA Jetson Nano/ reComputer J1010 (Jetson Nano)
- Webcam
- TensorFlow
- TensorRT
- PyTorch
- DeepStream SDK
- scikit-learn
- Openpose
- OpenCV
Here is a guide on how to use TensorRT on NVIDIA Jetson Nano. Take a look and hopefully try it out with any projects listed above! You can also take a look at Jetson Nano products below that can start you off in your journey.
NVIDIA Jetson Products you might wanna try now with TensorRT fasted inference!
- Jetson AGX Orin Dev Kit
- Jetson AGX Xavier H01 Kit
- reTerminal, powered by Raspberry Pi CM4
- reComputer J1010 (Jetson Nano)
- reComputer J1020 (Jetson Nano)
- reComputer J2012 (Jetson Xavier NX)
- reComputer J2032 (Jetson Xavier NX)

