Computer Vision 101: what is computer vision, and how to implement CV with edge devices?
Computer vision is what enables computers and systems to derive meaningful information from digital images, videos, and other visual inputs. You can think of AI as the brain of computers and computer vision being the eyes of computers. It would take action or make recommendations based on the information received, and it has been rapidly developing and even surpassing humans in solving visual tasks. It is currently vital in many industries, such as medical diagnosis, autonomous driving, video monitoring, etc.
But what exactly is computer vision?
Let’s walk you through the following concepts in this article:
- Definition of computer vision
- How does computer vision work
- Computer vision tasks, hello world of CV
- Popular Computer Vision frameworks, libraries, and dev platform
- Computer vision applications and tools
- Implement CV at the edge
Hopefully, by the end of this article, you will understand what computer vision is and even try your hand at some projects yourself!
How does Computer Vision Work?
Computer vision requires a lot of data to function effectively, it analyses data repeatedly until it is able to discern distinctions and recognize images. The algorithmic models will allow the machine to learn by itself rather than manually having someone program it to recognize an image.
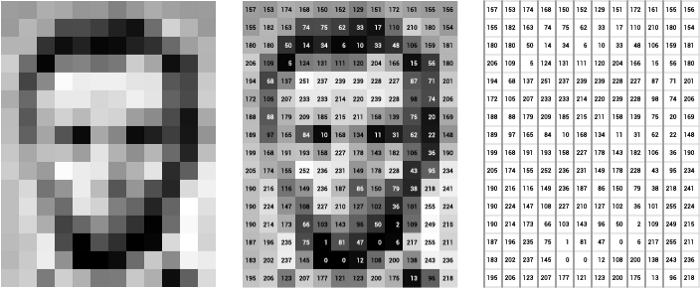
The picture below is a simple illustration of the greyscale image buffer of Abraham Lincoln. Each pixel is represented by a single-8bit number, ranging from 0 (black) to 255 (white). On the right is what the software would read when u input an image.
MNIST handwritten digit classification: “Hello World” of Computer Vision
The MNIST data set comes from the National Institute of Standards and Technology in the United States and is a reduced version of NIST (National Institute of Standards and Technology). The training set consists of handwritten numbers from 250 different people, 50% of which are high school students. 50% were from the Census Bureau staff, and the test set was the same proportion of handwritten digit data.
The MNIST handwritten digits dataset has a training set of 60,000 examples and a test set of 10,000 examples. It is a subset of the larger set provided by NIST. Figures have been size normalized and centered in a fixed-size image. The original creator of the MNIST kept a list of some of the methods tested on it. In their original paper, they used support-vector machines(SVM) to get an error rate of 0.8%.

Computer Vision Tasks
Image Classification
Image classification is a basic computer vision task where once the program detects an image, it is able to accurately predict the given image and classify it accordingly to its certain class (cat, orange, a human face).
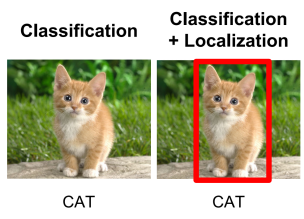
Image Localization
Image localization is a basic computer vision task that finds the object and draws a bounding box around it. The following image shows the difference between classification and localization.

Object Detection
Object detection classifies and detects all objects in the image. However, it assigns a class to each individual object and draws a bounding box around it. It is different from classification and localization, as seen in the image below.

Semantic Segmentation
Semantic segmentation is the next level to object detection. However, instead of drawing a bounding box around the object, it identifies the specific pixels in the image and segments them. Different classes would be assigned different colors, for example, grass = green and sheep = brown. It is commonly used for autonomous driving.
Instance Segmentation
Instance segmentation is a level-up version of semantic segmentation. Instead of assigning the same pixel values to all the objects in the same class, it segments and shows different instances of the same class. If there is more than one of the same object detected in the image, it would be labeled accordingly, as seen below, Sheep 1, Sheep 2, and Sheep 3. It is commonly used for crowd count.

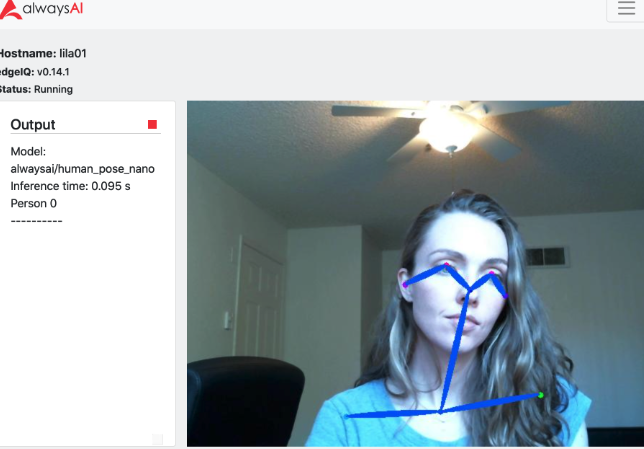
Pose Estimation
Pose estimation is a way of estimating the position and orientation of the joints of a human body. It predicts and tracks the movement of the object by finding the location of key points. Based on this information, it would be able to compare various movements and postures and draw insights. It is commonly used in AR/VR gaming and sports.
Popular Computer Vision Libraries and frameworks
PyTorch

PyTorch is an open-source ML library that uses dynamic computation, which allows for greater flexibility in building complex architectures. From the name, you can know that it supports Python very well. Although its underlying optimization is still in C, basically all its frameworks are written in Python, which makes you look at its source code more concise. It supports both CPU and GPU computations.
The PyTorch NGC Container is optimized for GPU acceleration and contains a validated set of libraries that enable and optimize GPU performance. This container also contains software for accelerating ETL (DALI, RAPIDS), Training (cuDNN, NCCL), and Inference (TensorRT) workloads.
NVIDIA Jetson is one of the best platforms to work with PyTorch models mainly due to the inference support, allowing it to run most common computer vision models that can be transfer-learned with PyTorch. Coupled with TensorRT and PyTorch API technology, you are able to seamlessly run PyTorch models on NVIDIA Jetson and also Raspberry Pi. Learn more on how to do so from this blog post by PyTorch.
If you just get started, don’t miss out Torchvision object detection fine-tuning tutorial. The torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision.
torchvision includes the following packages:
- vision.datasets: Several commonly used vision datasets, which can be downloaded and loaded, the main advanced usage here is to see how the source code writes your own subclass of Dataset
- vision.models: AlexNet, VGG, ResNet, and Densenet with trained parameters.
You can also find this tutorial about how to train a convolutional neural network for image classification using transfer learning. Read more about transfer learning at cs231n notes.
YOLOv5

YOLOv5 is a family of object detection architectures and models pre-trained on the COCO dataset and represent Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.YOLOv5 is implemented in PyTorch, which benefits from the mature PyTorch ecosystem: simpler implementation and easier deployment. YOLOv5 makes deployment to mobile devices simpler as the model can be easily compiled to ONNX and CoreML. Check our wiki on how to build a custom model with fewer datasets using YOLOv5 and deploying it to NVIDIA Jetson Nano and Xavier NX.
MMDetection

MMDetection is an open-source object detection toolbox based on the previously mentioned PyTorch. It consists of training recipes, pre-trained models, and dataset support. It runs on Linux, Windows, and macOS and requires Python 3.6+, CUDA 9.2+, and PyTorch 1.5+. They have also released a library mmcv for computer vision research. Through the method of module calling, we can implement a new algorithm with a small amount of code. Greatly improve the code reuse rate.

MMDeploy is an open-source deep learning model deployment toolset. It is a part of the OpenMMLab project. Check this guide to learn how to install MMDeploy on NVIDIA Jetson edge platforms such as Seeed’s reComputer.
OpenCV

OpenCV is one of the most popular open-source computer vision and ML software libraries. It was built to provide a common infrastructure for computer vision applications. It runs on Windows, Linux, Android, and macOS and can be used in Python, Java, C++, and MATLAB.
A few use cases of OpenCV include:
- 2D and 3D Feature Toolkits
- Facial Recognition Application
- Gesture Recognition
- Motion Understanding
- Human-Computer Interaction
- Object Detection
- Segmentation and Recognition
Learn how to use OpenCV from this crash course on youtube! You will get to learn topics such as Object Detection and Tracking, Edge and Face Detection, Image Enhancement, and many more.
OpenCV includes the GPU module, which contains all the GPU-accelerated stuff. With support from NVIDIA, work on the module began in 2010, ahead of its initial release in the Spring of 2011. It includes accelerated code for significant parts of the library, is still growing, and is adapting to new computing technologies and GPU architectures. Our partner alwaysAI also built OpenCV as a core piece of our edge runtime environment. That means in every alwaysAI application, you can add import cv2 and use OpenCV in your app. alwaysAI built a suite of tools around OpenCV to make the end-to-end process seamless and to help solve some of the common pain points unique to working with edge devices.

Keras
Keras is an open-source artificial neural network library written in Python that can be used as a high-level application programming interface for Tensorflow, Microsoft-CNTK, and Theano for deep learning model design, debugging, evaluation, application, and visualization.
Find all code examples at Keras.
- CutMix, MixUp, and RandAugment image augmentation with KerasCV
- Custom Image Augmentations with BaseImageAugmentationLayer
- Using KerasCV COCO Metrics
MATLAB
Embedded vision involves applying image processing to embedded systems, especially devices. The main aspects of the embedded vision development workflow include algorithm design, system modeling, collaboration, and deployment of vision algorithms. Engineers can use MATLAB® and Simulink® to develop and deploy image processing and computer vision systems to the embedded target hardware.
With MATLAB and Simulink, you can develop algorithms and model systems, integrate third-party software frameworks, and generate code for the target hardware platform. Check this guide on how to connect MATLAB with NVIDIA Jetson.
Explore the fundamentals of image processing using MATLAB.
NVIDIA VPI
NVIDIA® Vision Programming Interface (VPI) is a software library that implements computer vision and image processing algorithms on several computing hardware platforms available in NVIDIA embedded and discrete devices. VPI provides a unified API to both CPU and NVIDIA CUDA algorithm implementations, as well as interoperability between VPI and OpenCV, and CUDA.

TensorFlow

TensorFlow is an end-to-end open-source ML platform that is capable of performing a myriad range of tasks, including computer vision. TensorFlow Lite allows you to run models on mobile and edge devices, while TensorFlow JS is for the web. It runs on Windows, macOS, and WSL2, supporting Python, C, C++, Java, etc.
The main uses are:
- Image Classification
- Objection Detection and Segmentation
- Image Stylization
- Generative Adversarial Networks
Get started easily:
Check the Coral dev board at Seeed and enjoy an exclusive educational discount!

For on-device machine learning, check TensorFlow Lite
The key features of TensorFlow Lite are optimized for on-device machine learning, with a focus on latency, privacy, connectivity, size, and power consumption.
Get started quickly with reTerminal (powered by Raspberry Pi CM4) by Seeed.

To learn more about reTerminal, you can check out Seeed’s Wiki page.
Computer Vision Use Case
Retail – Zenus
Zenus offers fully integrated solutions for retail brands using computer vision. The Zenus Smart Camera captures data such as real-time foot traffic, demographics, and sentiment analysis.
Foot traffic information will be used to compute conversion rates and predict sales. Heat maps like this can help with understanding where to put high-profit margin products.

Demographics and sentiment analysis can help the store understand whether they are reaching the correct target audience for the respective products and whether their marketing techniques are working.

With all these, the retail store is able to further improve sales and increase customer engagement. Read more about how Zenus helps the retail industry using computer vision on Seeed’s blog post.
Agriculture – Intflow

Intflow’s EdgeFarm is an AI solution that perceives livestock injuries and diseases to help farmers manage and optimize livestock productivity. EdgeFarm collects biometric data of the livestock and uses computer vision to capture real-time data such as eating habits and weight gain in a day of the livestock. Based on this data, an action list will be provided to improve the productivity and efficiency of rearing livestock in the 21st century.
Read more on how Intflow’s EdgeFarm works on Seeed’s blog post.
Smart Home – Frigate

Frigate is an open-source network video recorder that can be implemented into your Home Assistant system. It uses OpenCV and TensorFlow to perform real-time object detection. You are able to view real-time visual footage of what is outside your door with Frigate.
The best thing is you can set it up yourself all for free, and you don’t have to pay any cloud management fee or any recurring security systems fee. Learn more on how to do it at Seeed’s blog post.
Hardware for Computer Vision
reComputer Nano/NX: real world AI at the Edge, starts from $199
Built with Jetson Nano 4GB/ Xavier NX 8GB/16GB
reComputer series for Jetson are compact edge computers built with NVIDIA advanced AI embedded systems: J10 (Nano 4GB) and J20 (Jetson Xavier NX 8GB and Jetson Xavier 16GB). With rich extension modules, industrial peripherals, and thermal management, reComputer for Jetson is ready to help you accelerate and scale the next-gen AI product by deploying popular DNN models and ML frameworks to the edge and inferencing with high performance.

- Edge AI box fits into anywhere
- Embedded Jetson Nano/NX Module
- Pre-installed Jetpack for easy deployment
- Nearly the same form factor as Jetson Developer Kits, with a rich set of I/Os
- Stackable and expandable
Jetson Benchmark: Jetson Xavier NX and Jetson AGX Orin MLPerf v2.0 Results
| Model | Jetson Xavier NX | Jetson AGX Xavier | Jetson AGX Orin |
| PeopleNet | 124 | 196 | 536 |
| Action Recognition 2D | 245 | 471 | 1577 |
| Action Recognition 3D | 21 | 32 | 105 |
| LPR Net | 706 | 1190 | 4118 |
| Dashcam Net | 425 | 671 | 1908 |
| Bodypose Net | 105 | 172 | 559 |
| ASR: Citrinet 1024 | 27 | 34 | 113 |
| NLP: BERT-base | 58 | 94 | 287 |
| TTS: Fastpitch-HifiGAN | 7 | 9 | 42 |
Get started with Computer Vision with easy-to-use developer tools.
- Edge AI No Code Vision Tool, Seeed latest open-source project for deploying AI applications within 3 nodes.
- NVIDIA DeepStream SDK delivers a complete streaming analytics toolkit for AI-based multi-sensor processing and video and image understanding on Jetson.
- NVIDIA TAO Tool Kit, built on TensorFlow and PyTorch, is a low-code version of the NVIDIA TAO framework that accelerates the model training
- alwaysAI: build, train, and deploy computer vision applications directly at the edge of reComputer. Get free access to 100+ pre-trained Computer Vision Models and train custom AI models in the cloud in a few clicks via enterprise subscription. Check out our wiki guide to get started with alwaysAI.
- Edge Impulse: the easiest embedded machine learning pipeline for deploying audio, classification, and object detection applications at the edge with zero dependencies on the cloud.
- Roboflow provides tools to convert raw images into a custom-trained computer vision model of object detection and classification and deploy the model for use in applications. See the full documentation for deploying to NVIDIA Jetson with Roboflow.
- YOLOv5 by Ultralytics: use transfer learning to realize few-shot object detection with YOLOv5, which needs only a very few training samples. See our step-by-step wiki tutorials
- Deci: optimize your models on NVIDIA Jetson Nano. Check the webinar at Deci of Automatically Benchmark and Optimize Runtime Performance on NVIDIA Jetson Nano and Xavier NX Devices


{kind=link}
{kind=link}