Facing The Gap between AI’s PoC to Production: Fewer Datasets, Faster Training
Machine learning is quite widely adopted in software industry applications like social media, YouTube, and E-commerce. It is not tough to acquire a billion-level data through the internet experience. However, looking into real-world applications, there are many other industries that only have access to small data, for example, medical imaging, manufacturing, and environmental research .

10K images or 500 or even 200 images?
?Use transfer learning along with Ultralytics YOLOv5 and Roboflow to train a dataset with very few samples.
A small amount of data is a big challenge in AI deployment, uneven data distribution is dramatically amplified. While we can build ML models that provide good accuracy on average, these models may still perform poorly on rare events that are less frequent in the data. From Andrew Ng‘s Bridging AI’s Proof-of-Concept to Production Gap: Production grade, AI is facing three main challenges:
1. Small Data
2. Generalizability and Robustness.
3. Change management

Fortunately, thanks to research algorithms, handling small data is in progress.
Here are some examples:
- Synthetic data generation (e.g., GANs)
- One/Few-shot Learning (e.g., GPT-3)
- Self-supervised Learning
- Transfer Learning
- Anomaly Detection
Fewer training samples, faster training time with transfer learning
Check out more details and ? try it follow our wiki!
Let’s take a look at how to use transfer learning along with YOLOv5 to train a dataset with very few samples. Here we will show the difference in training time between using a small dataset collected by ourselves and a large dataset available publicly. Also, we will use the trained model to perform faster inference on an edge device such as the NVIDIA Jetson platform with better accuracy.

Fewer training samples
Traditionally if you want to train a machine learning model, you would use a public dataset such as the Pascal VOC 2012 dataset which consists of around 17112 images.
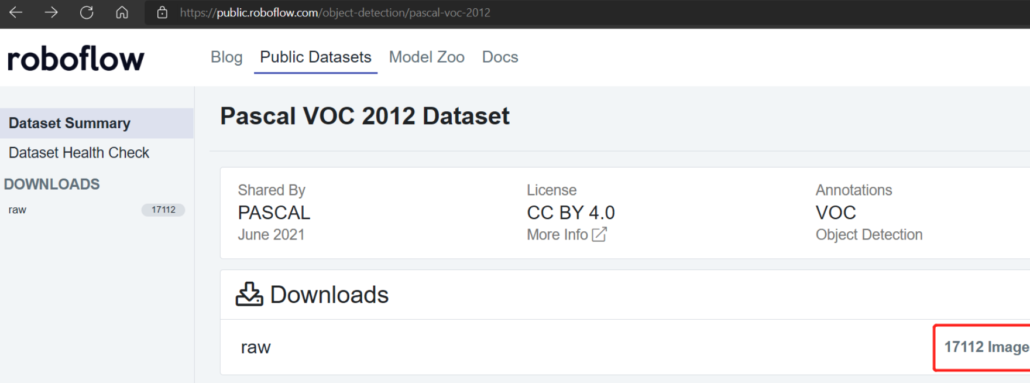
However, we can reduce the number of training samples by using a technique called transfer learning. In transfer learning, we first initialize a model with weights from a pre-trained model and then start training the machine learning model that we need. For this blog, we have used a dataset as small as 200 images.
What is YOLOv5?
YOLO is an abbreviation for the term ‘You Only Look Once’. It is an algorithm that detects and recognizes various objects in an image in real-time.YOLOv5 is the latest version of YOLO which performs much better than the previous iterations of YOLO and it is now based on the PyTorch framework.
Ultralytics HUB, no-code FREE YOLOv5 deployment tool!
Train models in 3 easy steps, ?try it now!

Access to all YOLOv5 architecture and models
The stages are broken down into 3 simple steps that anyone can follow: upload your data, train your model and then deploy it into the real world.
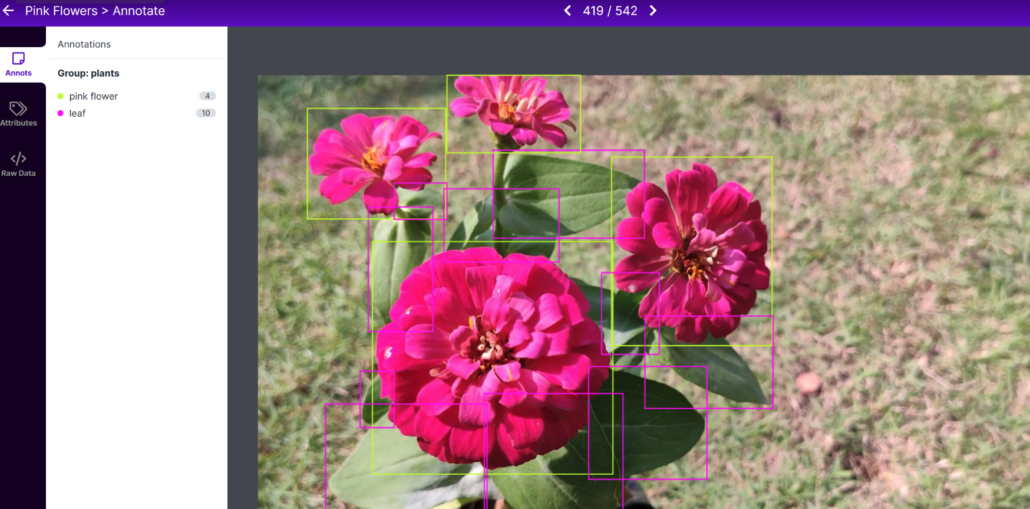
Roboflow: Annotate images super fast, right within your browser.
We use Roboflow to annotate images. Here we can directly import images or videos. If we import a video, it will be converted into a series of images. This tool is very convenient because it will let us help distribute the dataset into “training, validation, and testing”. Also, Roboflow will allow us to add further processing to these images after labeling them. Furthermore, it can easily export the labeled dataset into YOLOV5 PyTorch format which is what we exactly need!
Faster training times
If we use a public dataset such as the Pascal VOC 2012 dataset for training a machine learning model, it would take a long time for training to finish. To compare the results, we have trained our own dataset with 200 images and the Pascal VOC 2012 dataset on both a local PC and a Google Colab environment and obtained the following results
Local training
Here, training was done on an NVIDIA GeForce GTX 1660 Super Graphics Card with 6GB memory and we choose 100 epochs.
With 200 images dataset
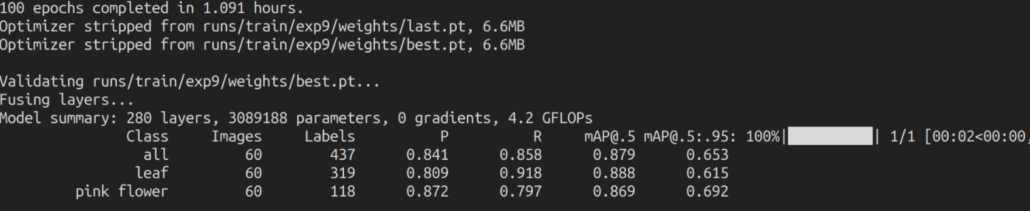
Here it took only about 1 hour to run 100 epochs. This is comparatively faster than training using public datasets.
With Pascal VOC 2012 dataset
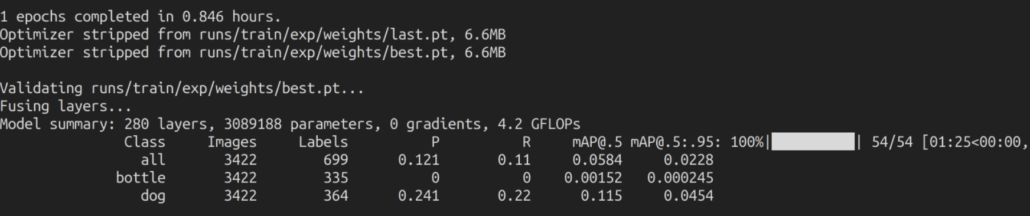
We found that it was taking about 50 minutes (0.846 hours * 60) to run 1 epoch, and therefore we stopped the training on 1 epoch. If we calculate the training time for 100 epochs, it would take about 50 * 100 minutes = 5000 minutes = 83 hours which is much longer than the training time for our own dataset.
Google Colab Training
Here, training was done on an NVIDIA Tesla K80 Graphics Card with 12GB memory and we choose 100 epochs.
With 200 images dataset
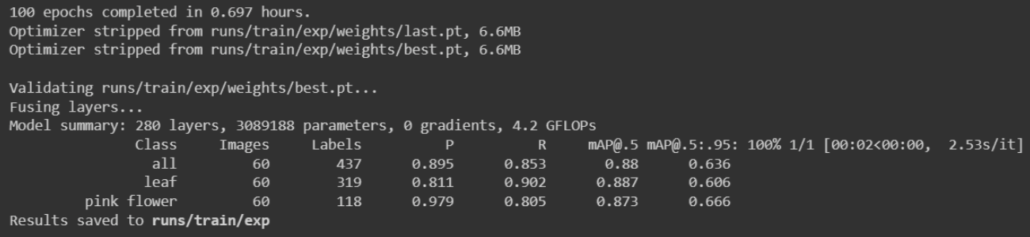
Here it took only about 42 minutes (0.697 hours * 60) to run 100 epochs. This is comparatively faster than training using public datasets.
With Pascal VOC 2012 dataset
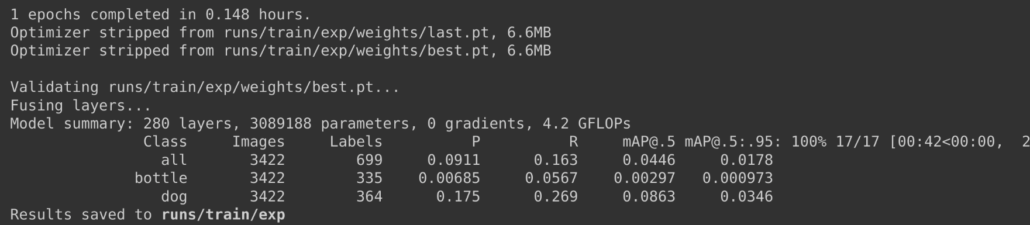
We found that it was taking about 9 minutes (0.148 hours * 60) to run 1 epoch, and therefore we stopped the training on 1 epoch. If we calculate the training time for 100 epochs, it would take about 9 * 100 minutes = 900 minutes = 15 hours which is much longer than the training time for the custom dataset.
Number of training samples and training time summary
From the results we obtained before, here is a summary of the number of training samples vs the training time.
| Dataset | Number of training samples | Training time on Local PC (GTX 1660 Super) | Training time on Google Colab (NVIDIA Tesla K80) |
|---|---|---|---|
| Custom | 542 | 2.2 hours | 1.3 hours |
| 240 | 1 hour | 42 minutes | |
| Pascal VOC 2012 | 17112 | 83 hours | 15 hours |
| Microsoft COCO 2017 | 121408 | 750 hours | 125 hours |
More accurate
After performing the training as explained above for the 200 images dataset, the accuracies we obtained were as follows:
For the local training, we obtained an accuracy of about 87.9% (mAP) and 65.3% (mAP) whereas, for the cloud training, we obtained an accuracy of about 88% (mAP) and 63.6% (mAP).
Faster Inference
After training the above dataset and obtaining the machine learning model, we went ahead and did inference on an NVIDIA Jetson device. We compared the results on both Jetson Nano and Jetson Xavier NX with the quantization set to FP16 and obtained the following results
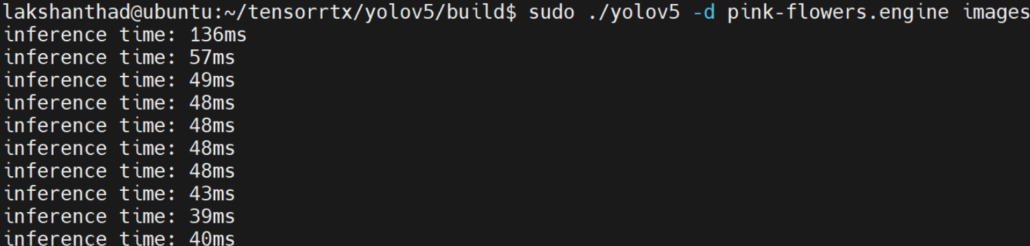
Jetson Nano: average as about 47ms(~21FPS)
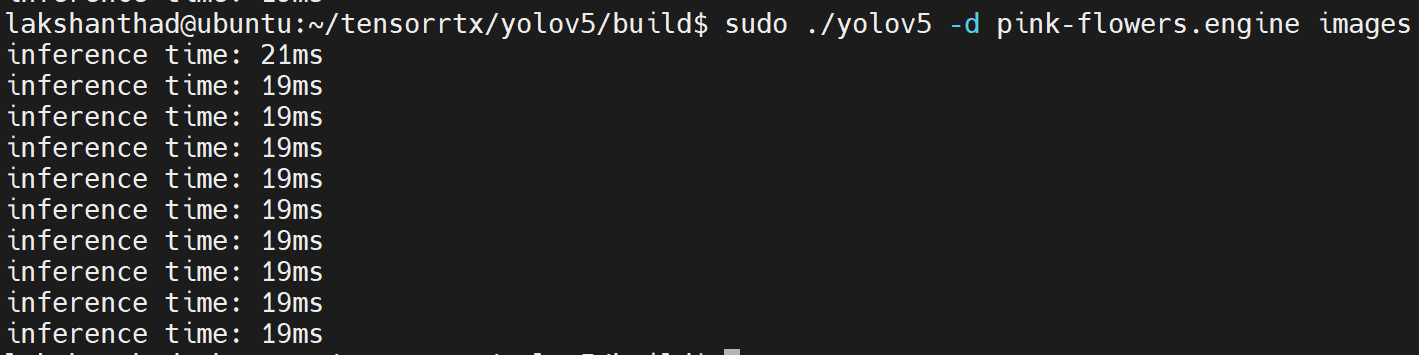
Jetson Xavier NX: the average as about 20ms(~50FPS).
More about the latest:
New arrival Edge AI devices powered by NVIDIA Embedded System

reComputer Jetson series are compact edge computers built with NVIDIA advanced AI embedded systems: Jetson Nano and Xavier NX. With rich extension modules, industrial peripherals, thermal management combined with decades of Seeed’s hardware expertise, reComputer Jetson is ready to help you accelerate and scale the next-gen AI product emerging diverse AI scenarios.

reComputer Jetson is compatible with the entire NVIDIA Jetson software stack, cloud-native workflows, and industry-leading AI frameworks, helping deliver seamless AI integration.
Let us know how will you play with few-shot object detection? Discuss with us on Discord #EdgeAI channel! Let us know what’s the next are looking forward! Start your next transfer learning assisted AI application along with Ultralytics YOLOv5 to train a dataset with very few samples. ?

