Fast(er) Machine Learning Inference on Raspberry Pi SBC – Four optimization techniques
A while ago I made a video on semantic segmentation with new Raspberry Pi HD camera module – I used MobileNet v1 backend SegNet-basic for segmentation task and it was running rather slow on Raspberry Pi, which was noticed by people in the comments.
I had to admit that Raspberry Pi 4 is not the best SBC for Machine Learning tasks, since it doesn’t have a hardware accelerator that can be used to speed up the inference and has to rely on CPU. Since then I have been working on applications for Raspberry Pi 4 Compute Module inside of reTerminal – some of which included Machine Learning demos, such as age/gender recognition, object detection, face anti-spoofing and so on.

Here is the list of four techniques, that can be helpful when aiming for running real-time model inference on Raspberry Pi 4. Ready? Let’s go!
Designing smaller networks
If the goal is simple enough (image classification of < 100 classes or object detection of < 10 classes or similar), a smaller network can achieve acceptable accuracy and run very fast. For example, MobileNet v1 alpha 0.25 YOLOv2 network trained to detect only one class of objects (human faces) achieves 62.5 FPS without any further optimization.
Vanilla TensorFlow Lite FP32 inference:

Quantization
Quantization is process of reducing precision for NN network weights, usually from FP32 to INT8.
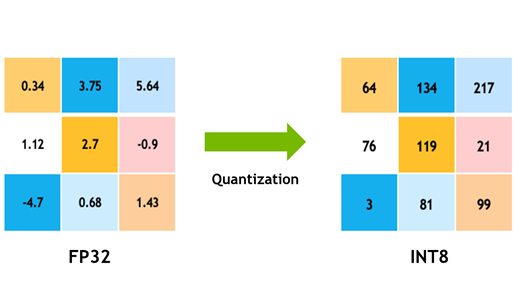
It reduces the size by 4x and latency by ~60-80% using default TensorFlow Lite kernels. There are two kinds of quantization process in TensorFlow: post-training quantization and quantization-aware training or QAT. Post-training quantization usually brings a small accuracy loss, which can be minimized by using QAT – quantization-aware training, which is the process of fine-tuning network with quantization nodes inserted.
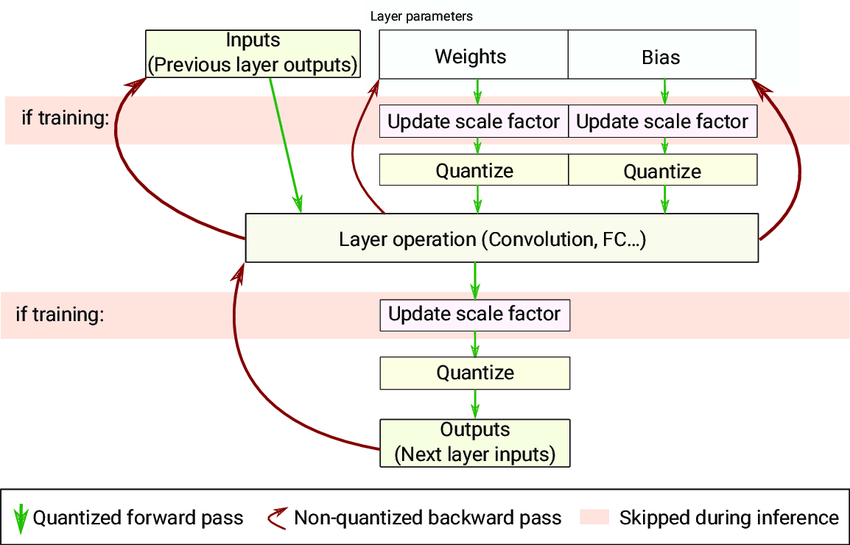
For further reading have a look at TensorFlow Lite documentation and convert.py script of aXeleRate, my personal project that simplifies training of common vision networks for inference on embedded devices.
Vanilla TensorFlow Lite INT8 inference:

Using optimized kernels
Inference speed can be improved by utilizing frameworks that have operation kernels optimized for specific CPU instructions set, e.g. NEON SIMD (Single Instruction Multiple Data) instructions for ARM. Examples of such networks include ARM NN and XNNPACK.
Arm NN SDK is a set of open-source software and tools that enables machine learning workloads on power-efficient devices.
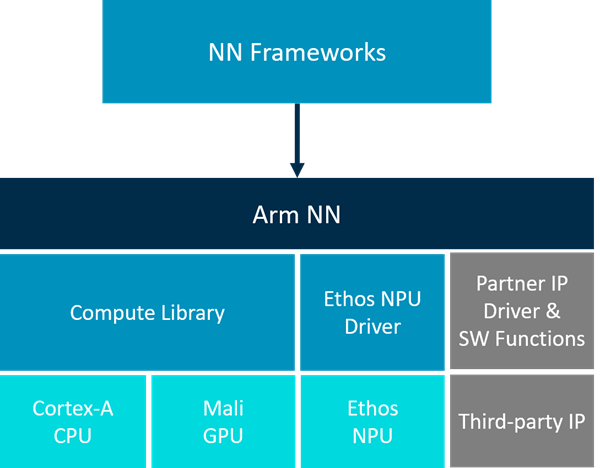
The description and provided benchmarks look promising, but the installation procedure on latest Raspberry Pi OS is painful at the moment – the only proper way to install latest version of ARM NN currently is cross-compiling from source. There are binaries available for Debian Bullseye, but Raspberry Pi OS is still at Debian Buster. The inference test results with my benchmark scripts were mixed, for a single model it showed worse performance than even vanilla TensorFlow Lite, but it turned out to be faster in multi-model inference, possibly due to more efficient multi-processing utilization.
ARM NN FP32 inference:

XNNPACK is a library for accelerating neural network inference for ARM, x86, and WebAssembly architectures in Android, iOS, Windows, Linux, macOS environments.
It is integrated in TensorFlow Lite as a delegate, which is enabled by default for Android build, but for other environments needs to be enabled manually – thus if you’d like to use XNNPACK on Raspberry Pi 4, you’ll need either to build TensorFlow Lite Interpreter package from source or download one of the third-party binaries.
To build TensorFlow Lite Interpreter pip package with XNNPACK (both FP32 and INT8 optimized kernels) do the following:
git clone https://github.com/tensorflow/tensorflow.git
cd tensorflow
nano tensorflow/lite/tools/pip_package/build_pip_package_with_bazel.shThen change Bazel build options from
# Build python interpreter_wrapper.
cd "${BUILD_DIR}"
case "${TENSORFLOW_TARGET}" in
armhf)
BAZEL_FLAGS="--config=elinux_armhf
--copt=-march=armv7-a --copt=-mfpu=neon-vfpv4
--copt=-O3 --copt=-fno-tree-pre --copt=-fpermissive
--define tensorflow_mkldnn_contraction_kernel=0
--define=raspberry_pi_with_neon=true"
;;
aarch64)
BAZEL_FLAGS="--config=elinux_aarch64
--define tensorflow_mkldnn_contraction_kernel=0
--copt=-O3"
;;
native)
BAZEL_FLAGS="--copt=-O3 --copt=-march=native"
;;
*)
BAZEL_FLAGS="--copt=-O3"
;;
esacto
# Build python interpreter_wrapper.
cd "${BUILD_DIR}"
case "${TENSORFLOW_TARGET}" in
armhf)
BAZEL_FLAGS="--config=elinux_armhf
--copt=-march=armv7-a --copt=-mfpu=neon-vfpv4
--copt=-O3 --copt=-fno-tree-pre --copt=-fpermissive
--define tensorflow_mkldnn_contraction_kernel=0
--define=raspberry_pi_with_neon=true
--define=tflite_pip_with_flex=true
--define=tflite_with_xnnpack=true
--define=xnn_enable_qs8=true"
;;
aarch64)
BAZEL_FLAGS="--config=elinux_aarch64
--define tensorflow_mkldnn_contraction_kernel=0
--define=tflite_pip_with_flex=true
--define=tflite_with_xnnpack=true
--define=xnn_enable_qs8=true
--copt=-O3"
;;
native)
BAZEL_FLAGS="--copt=-O3 --copt=-march=native
--define=tflite_pip_with_flex=true
--define=tflite_with_xnnpack=true
--define=xnn_enable_qs8=true"
;;
*)
BAZEL_FLAGS="--copt=-O3
--define=tflite_pip_with_flex=true
--define=tflite_with_xnnpack=true
--define=xnn_enable_qs8=true"
;;
esacAnd then finally start building process with:
sudo CI_DOCKER_EXTRA_PARAMS="-e CI_BUILD_PYTHON=python3.7 -e CROSSTOOL_PYTHON_INCLUDE_PATH=/usr/include/python3.7" \
tensorflow/tools/ci_build/ci_build.sh PI-PYTHON37 \
tensorflow/lite/tools/pip_package/build_pip_package_with_bazel.sh aarch64This is cross-compilation, so the build process needs to be done on your Linux x86 compatible computer and NOT Raspberry Pi! Compilation will take a while – if you encounter an error, try switching to an earlier commit, since it is not uncommon for builds on master branch of TensorFlow to fail.
Link to the pre-built package is available from Seeed studio Wiki page about using TensorFlow Lite on reTerminal.
XNNPACK delegate Tensorflow Lite FP32 inference:

Main problem with optimized kernels is the uneven support of different architectures/NN operators/precision types in different frameworks. For example INT8 optimized kernels are work-in-progress both in ARM NN and XNNPACK. The support for INT8 optimized kernels in XNNPACK was added very recently and seems to bring modest performance improvement, of about ~30%, depending on operators used in the model.
While researching model inference optimization techniques, I stumbled upon another promising lead in Tensorflow Github Pull Request, adding optimized kernels for dynamically quantized models, link to the PR in the video description
The developer claims 3-4x latency improvement, but currently it is only limited to very specific set of models. A PR to allow more convenient usage is in development.
Pruning and sparse inference
Pruning is a process of fine-tuning trained neural network to find weights, that do not contribute to correct predictions and removing them. Pruning is very helpful for reducing the size of the model for compression by simply setting the “dead” weights to zeros, but using it for reducing latency is trickier, since that requires removing the connections themselves, which can lead to significant accuracy loss.

Using Tensorflow Model Optimization toolkit Experimentally it was possible to achieve up to 80% sparsity with negligible impact on accuracy. Check Google AI blog article here and a guide to pruning with Tensorflow model optimization toolkit here.
To summarize, the fact that a board doesn’t have a dedicated hardware to accelerate NN inference, doesn’t mean it is useless for ML though – there are some optimization options, that allow achieving —acceptable— inference speeds. Applying some of these techniques, such as optimized kernels can be a bit tricky though and requires some tweaks to the model architecture and (possibly) compiling inference packages from source, since a lot of optimizations are currently on the bleeding edge of development.
Oh, and while you at at, make sure you avoid thermal throttling when running optimized inference on Raspberry Pi 4 – get yourself one of these nice cooling towers and don’t set your Pi on fire.
