Multi-stage inference with Edge Impulse/Tensorflow Lite – reTerminal (Raspberry Pi CM4 inside)
In comments to our articles and videos we get occasional questions about such tasks as face recognition, license plate recognition, emotion/gender recognition and etc. These are all cases when you want to utilize multi-stage inference. Multi-stage inference in Computer Vision most of the time involves a combination of object detection and image classification in a single multi-model pipeline.
What is the main benefit of using multi-stage inference?
Object detection networks in general, and the ones used on embedded devices in particular, are not very good at distinguishing between multiple similar classes of objects.

So, what we see very often is using a detection networks to detect a large class of objects, for example faces or cars or dogs and then cropping and re-scaling the result of detection to be fed to image classification network, which gives a much more nuanced output, for example, the emotion on the face, car model or dog breed.
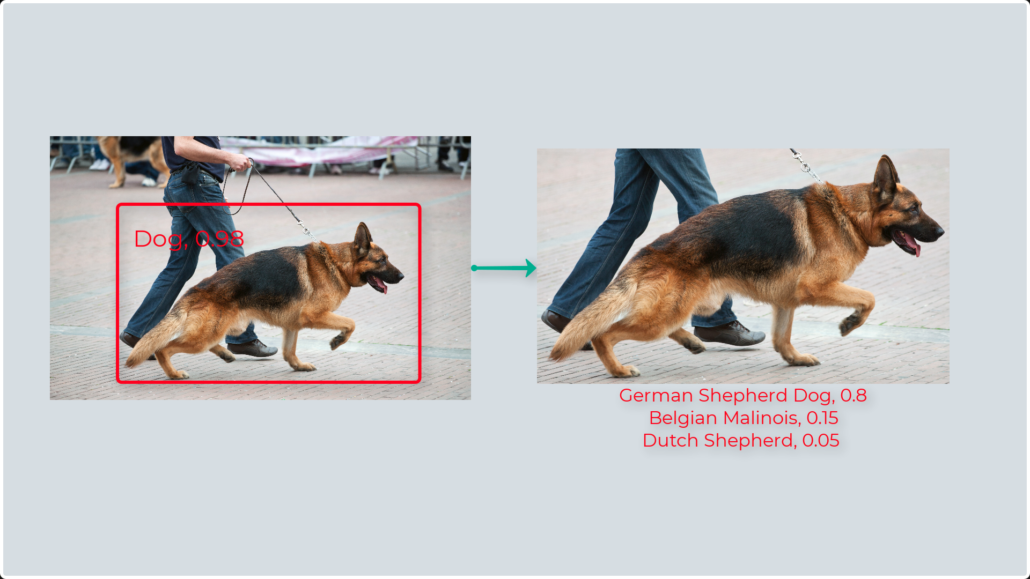
Another popular use case for multi-stage inference is OCR (or optical character recognition) – instead of performing detection of every character in the whole image, which is resource-intensive and prone to errors, most often the text is first detection and then recognition performed on pieces of text cropped out of the large image.
For this article, let’s take car model recognition as an example. In Edge Impulse train a car detector – this should be fairly easy, since we are using transfer learning and the base model already was trained to detect cars, so it contains the necessary feature maps.
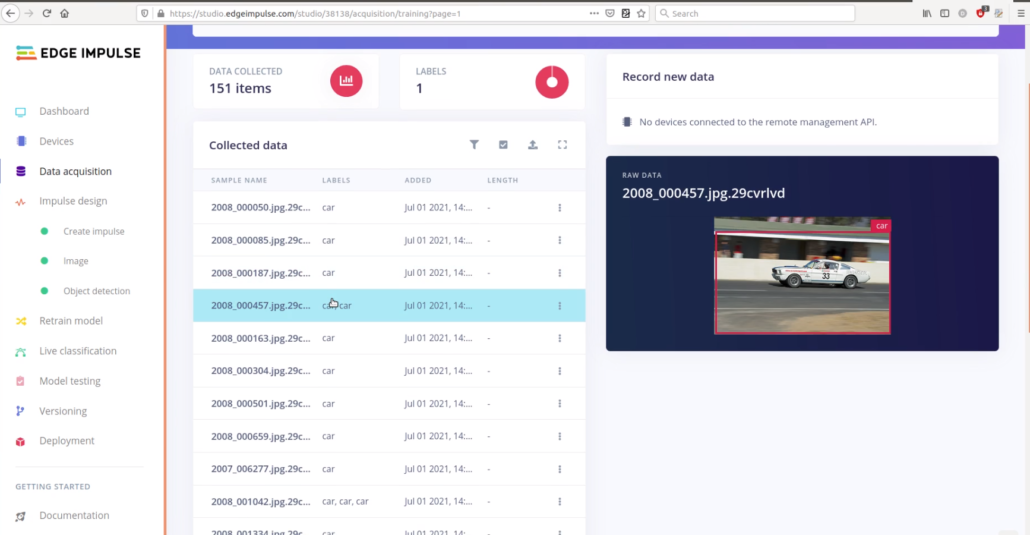
For image recognition model training, we’re going to use a subset of Stanford Cars dataset, with 6 car model classes – I picked 6 classes of cars, that I think I’ll likely to encounter while walking outside in Shenzhen, China.
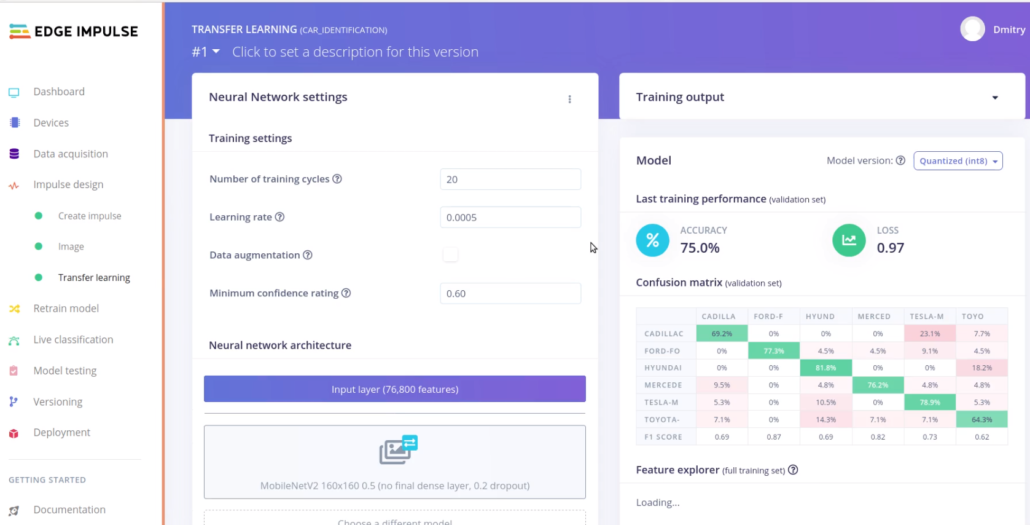
After training the models and optionally, checking the detection and recognition accuracy on pictures from the internet, let’s deploy them to an embedded device. I have used reTerminal, a Raspberry Pi Compute Module 4 based development board with a touchscreen in a sturdy plastic case – it comes in handy while on field trips like this one.
Raspberry Pi Compute Module 4 has the same CPU as Raspbery Pi 4 development board, but has an option to include onboard eMMC memory – the module in reTerminal has 4 GB or RAM and 32 GB of eMMC.
First of all you’ll need to download both detection and classification models with the help of edge-impulse-linux-runner. To install edge-impulse-runner on reTerminal (or Raspberry Pi) consult the official documentation. After it is installed run the following commands to download models:
edge-impulse-linux-runner --download car_detector.eim
edge-impulse-linux-runner --clean
edge-impulse-linux-runner --download car_classifier.eimThe multi-stage inference script is very similar to image classification/object detection scripts, except as you might have guessed it has both models – you can find the code in this Github repository. Remember to install all the dependencies before running the code:
sudo apt-get install libatlas-base-dev libportaudio0 libportaudio2 libportaudiocpp0 portaudio19-dev
pip3 install install edge_impulse_linux -i https://pypi.python.org/simple
python3 multi_stage.py car_detector.eim car_classifier.eim Alternatively, you can do multi-stage inference using another inference framework of your choice. For this have a look at Jupyter Notebook I prepared, which uses aXeleRate, a Keras-based framework for AI on the edge. There I trained small MobileNet v1 alpha 0.25 YOLOv3 to detect vehicles and slightly larger MobileNet v1 alpha 0.5 for classifying all cars from Standford cars dataset. Jupyter Notebook includes training examples – if you’d like to run them on a Raspberry Pi or reTerminal, download the code from here and run
python3 multi_stage_file.py --first_stage yolo_best_recall.tflite --second_stage classifier_best_accuracy.tflite --labels labels.txt --file ../../sample_files/cars.mp4 for running inference on video file and
python3 multi_stage_stream.py --first_stage yolo_best_recall.tflite --second_stage classifier_best_accuracy.tflite --labels labels.txt To run inference on video stream from web camera.
In conclusion, do we really need multi-stage inference and could object detector do both detection and fine-grained classification? There are some models, that can perform detection and large class-size classification pretty well, such as YOLO9000, but these are not suitable for running on embedded devices with constrained resources. So, for now, multi-stage inference is the best technique we have in our Computer Vision arsenals for this type of applications.