Offline Speech Recognition on Raspberry Pi 4 with Respeaker
Note: This article by Dmitry Maslov originally appeared on Hackster.io
In this article, we’re going to run and benchmark Mozilla’s DeepSpeech ASR (automatic speech recognition) engine on different platforms, such as Raspberry Pi 4(1 GB), Nvidia Jetson Nano, Windows PC, and Linux PC.
2019, last year, was the year when Edge AI became mainstream. Multiple companies have released boards and chips for fast inference on the edge and a plethora of optimization frameworks and models have appeared. Up to date, in my articles and videos, I mostly focused my attention on the use of machine learning for computer vision, but I was always interested in running deep learning-based ASR projects on an embedded device. The problem until recently was the lack of simple, fast and accurate engines for that task. When I was researching this topic about a year ago, the few choices for when you had to run ASR (not just hot-word detection, but large vocabulary transcription) on, say, Raspberry Pi 3 were:
- CMUSphinx
- Kaldi
- Jasper
Links:
Python 3 Artificial Intelligence: Offline STT and TTS
The Best Voice Recognition Software for Raspberry Pi
And a couple of other ones. None of them were easy to set up and not particularly suitable for running in resource constrained environment. So, a few weeks ago, I started looking into this area again and after some search has stumbled upon Mozilla’s DeepSpeech engine. It has been around for a while, but only recently (December 2019) they have released a 0.6.0 version of their ASR engine, which comes with.tflite model among other significant improvements. It has reduced the size of the English model from 188 MB to 47 MB. “DeepSpeech v0.6 with TensorFlow Lite runs faster than real-time on a single core of a Raspberry Pi 4.”, claimed Reuben Morais from Mozilla in the news announcement. So I decided to verify that claim myself, run some benchmarks on different hardware and make my own audio transcription application with hot word detection. Let’s see what the results are.
Hint: I wasn’t disappointed.

Actually I was as happy as this Firefox!
Installation
Raspberry Pi 4/3B
The pre-built wheel package for arm7 architecture is set to use.tflite model by default and installing it as easy as just
pip3 install deepspeechThis is it really! The package is self-contained, no Tensorflow installation needed. The only external dependency is Numpy. You’ll need to download model separately, we’ll cover it in the next section.
Nvidia Jetson Nano
As of the day of writing this article(1/22/2020) the pre-built wheel for arm64 architecture uses large.pbmm model by default. So, if you download it from DeepSpeech releases on Github, you’ll have an unpleasant surprise. With the swap file expanded to 4 GB, Jetson Nano can run the full model, but it takes about 18 seconds for 1.9-second file… There is a preview wheel with.tflite model support enabled available for download at https://community-tc.services.mozilla.com/api/queue/v1/task/KZMAnYo2Qy2-icrTp5Ldqw/runs/0/artifacts/public/deepspeech-0.6.1-cp37-cp37m-linux_aarch64.whl
You can download it and install with
python3.7 -m pip install --user deepspeech-0.6.1-cp37-cp37m-linux_aarch64.whlWe need to have Python 3.7 installed! Nvidia Jetson comes with Python 3.6 by default.
Windows 10/Linux
For Windows and Linux you’ll need to download.tflite enabled version of pip package.
pip3 install deepspeech-tfliteIf you’re using Python 3.8 you’ll likely to encounter DLL loading error on Windows. It can be corrected fairly simple with a little change to DeepSpeech package code, but I suggest you just install the version for Python 3.7, which works flawlessly.
If you have NVIDIA GPU and CUDA 10 installed you can opt for GPU-enabled version of Deepspeech
pip3 install deepspeech-gpuBenchmarking
Let’s download the models, language model binary and some audio samples.
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.6.1/deepspeech-0.6.1-models.tar.gztar xvf deepspeech-0.6.1-models.tar.gzDownload example audio files
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.6.1/audio-0.6.1.tar.gztar xvf audio-0.6.1.tar.gzRaspberry Pi 4 run:
deepspeech --model deepspeech-0.6.1-models/output_graph.tflite --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wavIf successful you should see the following output
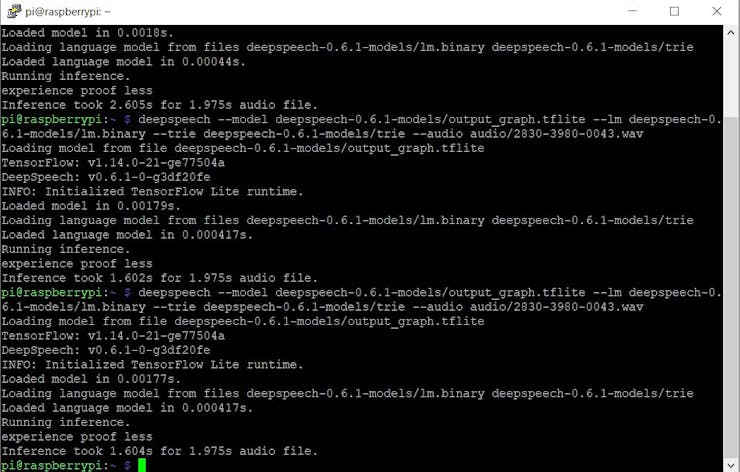
Not bad! 1.6 seconds for 1.98 seconds sound file. It IS faster than real time.
Nvidia Jetson Nano run:
deepspeech --model deepspeech-0.6.1-models/output_graph.tflite --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wav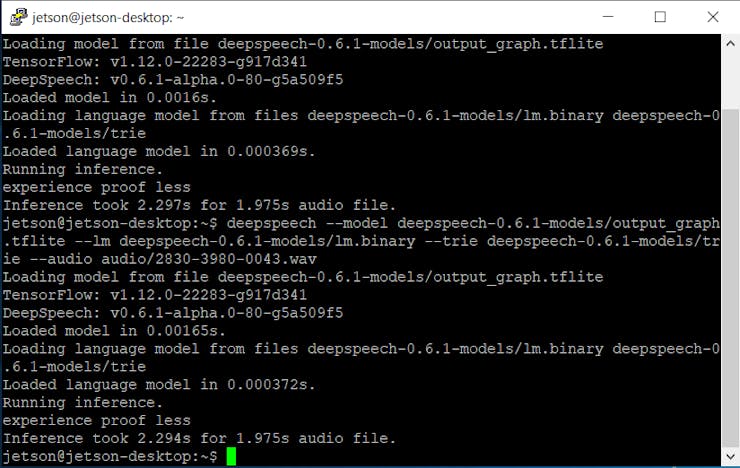
Hm.. a little bit slower than Raspberry Pi. That is expected since Nvidia Jetson CPU is less powerful than Raspberry Pi 4. There are no pre-built binaries for arm64 architecture with GPU support as of this moment, so we cannot take advantage of Nvidia Jetson Nano’s GPU for inference acceleration. I don’t think this task is on the DeepSpeech team roadmap, so in the near future, I’ll do some research here myself and will try to compile that binary to see what speed gains can be achieved from using GPU. But seconds is still pretty decent speed and depending on your project you might want to choose to run DeepSpeech on CPU and have GPU for other deep learning tasks.
Windows 10/Linux
deepspeech --model deepspeech-0.6.1-models/output_graph.tflite --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wav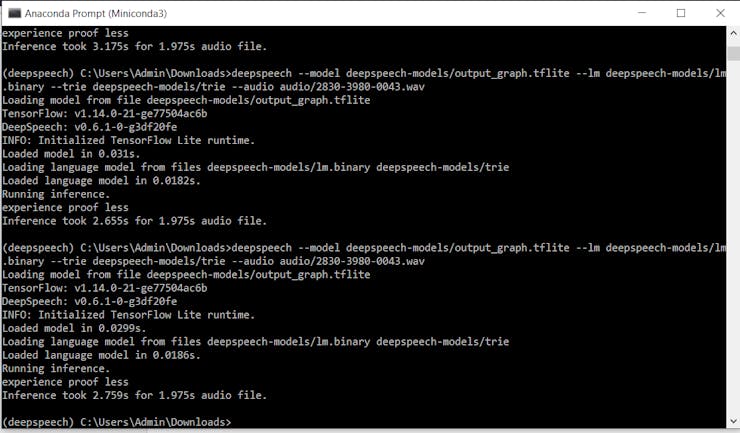
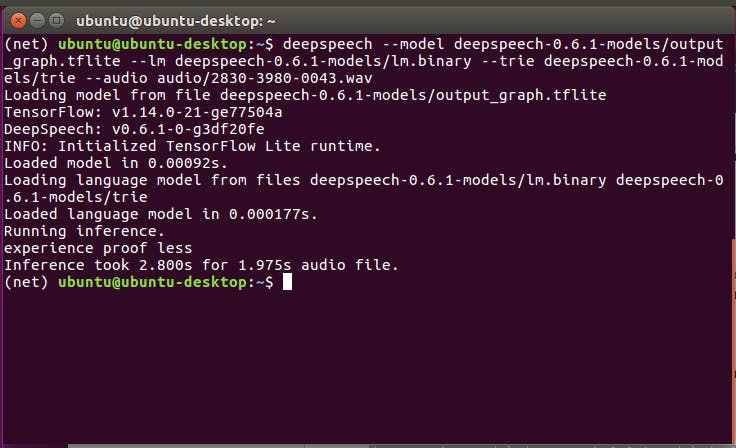
Or if using GPU enabled version:
deepspeech --model deepspeech-0.6.1-models/output_graph.pbmm --lm deepspeech-0.6.1-models/lm.binary --trie deepspeech-0.6.1-models/trie --audio audio/2830-3980-0043.wav
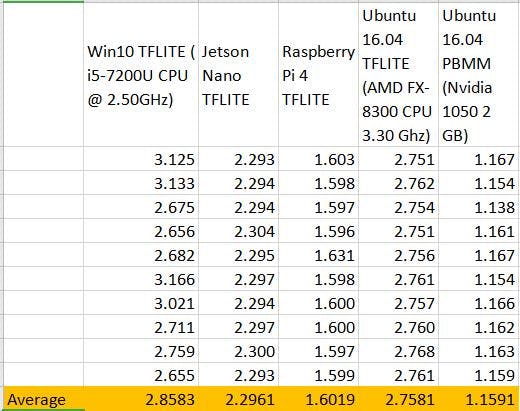
As you see.tflite model achieves sub-real time on modern CPU systems, which is great news for people creating offline ASR applications.
Here is comparison result table:
Well, we did benchmarking with pre-recorded sound samples, but we really want to do some real-time transcribing. Let’s do that!
Download DeepSpeech examples from https://github.com/mozilla/DeepSpeech-examples
Navigate to mic_vad_streaming and install the dependencies with
pip3 install -r requirements.txtConnect the microphone to your system (I am using Raspberry Pi 4 1 GB). For the microphone, despite you can use any microphone, including your laptop’s inbuilt microphone, the quality of the sound really influences the results a lot. For this demo, I am using ReSpeaker USB Mic Array from Seeed Studio. It features the support of Far-field voice pick-up up to 5m and 360° pick-up pattern with following acoustic algorithms implemented: DOA(Direction of Arrival), AEC(Automatic Echo Cancellation), AGC(Automatic Gain Control), NS(Noice Suppression).

python3 ../DeepSpeech-examples/mic_vad_streaming/mic_vad_streaming.py -m ./output_graph.tflite -l lm.binary -t trie -v 3Execute this command from the folder with models. -v argument allows you to tweak the threshold of VAD(Voice activity detection). Here is the result of the demo.
Okay, great! Can we improve on that? Yes. We really don’t want our device to be transcribing the conversations all the time. Talk about privacy nightmares and wasted electricity.

It/He/She? is listening… Or maybe not. If it’s not Opensource you’d never know.
So we will want to implement so-called wakeup word detection. DeepSpeech is a general-purpose ASR engine and for the wake-up words we need to use something more light-weight and more accurate for short voice commands. I tried two frameworks for hot word detection on Raspberry Pi: Snowboy and Porcupine. The first one ran successfully, but only supported Python 2… A closer look at snowboy Github repo shows that it is probably not under active development now. Porcupine worked great and it is free for non-commercial applications. So, I wrote a little script that would run wake-up word detection and upon its detection start transcribing speech with DeepSpeech ASR. It would stop transcribing when “stop transcribing” keyword is recognized in the transcription. After that, it goes back to waiting for wake-up word mode.
Here is the result of the script – quite neat and completely offline.
To reproduce the result yourself, download the files from Porcupine Github and make the folder with the following file structure (I cannot redistribute Porcupine libraries and code, so I just uploaded my own script to Github together with folder structure).

You will also need to make a one-line change to resources/util/python/util.py:
elif 'rev 3' in model_info:
return 'cortex-a53'It is hacky approach, but unfortunately Porcupine is not officially supported on Raspberry Pi 4… Despite it is the same architecture with Raspberry Pi 3. So if you wouldn’t change “rev 5” to “rev 3” it wouldn’t start.
I hope you enjoyed this article and it was useful for you. In my opinion, 2020 will be the year reliable offline NLP and ASR will come to Edge devices, such as our phones, smart assistants and other embedded electronics. If you’d like to participate in that move, you’re welcome to have a look at Mozilla’s DeepSpeech Github and try training your own model, for different languages or different vocabulary. The thing I really like about DeepSpeech apart from being so easy to use, is that it is completely open-source and open to contributions.
The hardware for this article was kindly provided by Seeed Studio. Check out
Raspberry Pi 4, ReSpeaker USB Mic Array and other hardware for makers at Seeed Studio store!
Stay tuned for more videos and articles!


Hi I am trying to follow your example but stumbled upon the following error
curl: (6) Could not resolve host: xvf
curl: (6) Could not resolve host: deepspeech-0.6.1-models.tar.gz
Nevermind i found the problem with my syntax…